- 1 Intro
- 2 Anwendungsgebiete
- 2.1 XSLT - die Programmiersprache im XML Bereich
- 2.2 Aktuelle und vergangene Anwendungen
- 2.3 Professionelle XML Verarbeitung
- 2.4 Technische Dokumentation
- 3 Wichtige Konzepte
- 3.1 Push vs. Pull Stylesheets
- 3.2 Eindeutigkeit der Regelbasis
- 3.3 Namespaces
- 3.4 Schemata
- 3.5 Standards
- 3.5.1 DITA
- 3.5.2 DITA Inhaltsmodell
- 3.5.1 DITA
- 4 Ausgewählte Themen
- 4.1 Transformationen mit XSLT
- 4.1.1 Vortransformationen
- 4.1.2 Komplexe XML-2-XML Transformationen
- 4.1.2.8 Vererbung
- 4.1.2.8 Vererbung
- 4.1.3 XSLT Streaming
- 4.1.3.1 XSLT Akkumulator
- 4.1.3.2 XSLT Iterator
- 4.1.4 Reguläre Ausdrücke
- 4.1.5 Modus vs. Tunnel Lösung
- 4.1.6 Identifikation mit
generate-id()
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.7 Webservice Calls mit doc() und unparsed-text()
- 4.1.8 Stylesheet-Parameter auf der Kommandozeile
- 4.1.9 Leerzeichenbehandlung
- 4.1.10 Mit
translate
Zeichen ersetzen
- 4.1.10.1 Spass mit dem Sequenzvergleich
- 4.1.11 Character Mappings in der Ausgabe
- 4.1.12 JSON mit XSLT 1.0 und Python lxml
- 4.1.1 Vortransformationen
- 4.2 Abfragen mit XQuery
- 4.2.5 XQuery als Programmiersprache
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.5.3.2 SQL Views in MarkLogic
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.6 Hilfreiche XQuery Schippsel
- 4.2.5 XQuery als Programmiersprache
- 4.3 XML Datenbanken
- 4.3.1 Connector zu Marklogic in Oxygen
- 4.3.2 Bi-Temporale Dokumente
- 4.3.2.1 Anlegen des Testszenarios auf der ML Konsole
- 4.3.2.2 Ausführen einiger Beispiel-Queries
- 4.3.3 Webapps mit MarkLogic
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.4 Dokument-Rechte in MarkLogic
- 4.3.5 MarkLogic Tools
- 4.3.5.1 EXPath Konsole
- 4.3.5.2 mlcp - MarkLogic Content Pump
- 4.3.5.3 Deployment-Tools
- 4.4 XSL-FO mit XSLT1.x
- 4.5 Testing
- 4.5.1 Validierung mit Schematron
- 4.5.2 Erste Schritte mit XSpec
- 4.5.1 Validierung mit Schematron
- 4.6 Performanz-Optimierung
- 4.1 Transformationen mit XSLT
- 5 Zusätzliches Know-How
- 5.1 XML Editoren
- 5.2 Quellcode-Versionskontrolle
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.2.2 GIT Kommandos
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.1 XML Editoren
- 6 Glossary
- 7 Tektur CCMS
4.3.1 Connector zu Marklogic in Oxygen
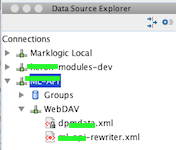
Marklogic bietet zwar auf Port 8000 per Default ein Query Console im Browser, mit der man bestimmte Sachen ausprobieren kann. Komfortabler arbeitet man aber mit einem Oxygen-Connector
. Hier öffnet man den Data Source Explorer und konfiguriert eine neue Datenquelle:
oXygen Datasource Explorer View öffnen
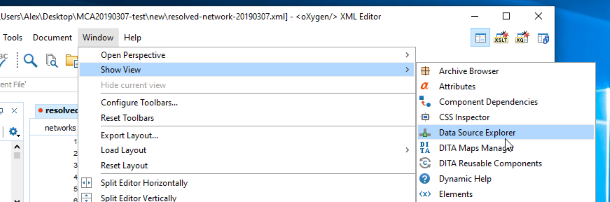
Dazu muss man den Marklogic Treiber installieren ↗ und diesen im folgenden Screen verfügbar machen.
Neue Datenquelle in oXygen konfigurieren
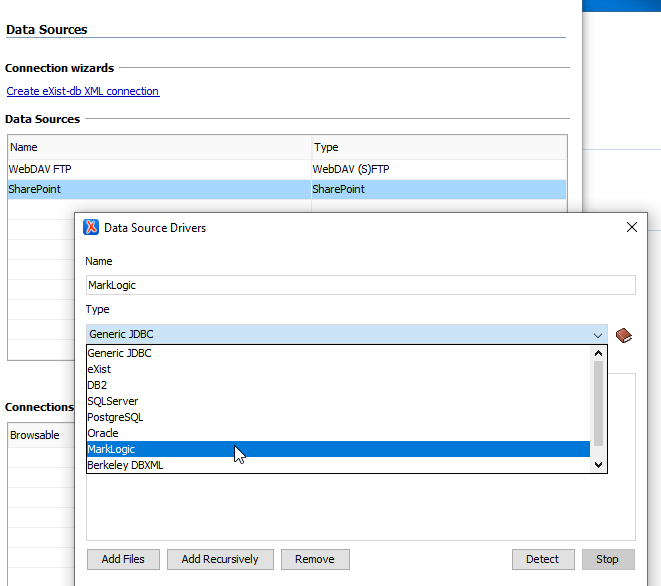

Das Jar sollte an einem soliden Ort abgespeichert werden, da hier nur ein Verweis auf diesen Ort gesetzt wird.

Neue oXygen Treiberdatei auswählen
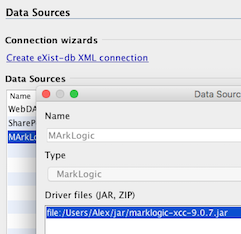
Natürlich ist auf der Serverseite auch eine Einstellung notwendig. Man wechselt als Admin in den Bereich App Servers und fügt einen neuen WebDAV Server
hinzu. Ggf. muss man bei der Auswahl der Datenbank diese noch auf "automatische Directory Erzeugung" umstellen.
Wechseln in die MarkLogic Appserver Verwaltung
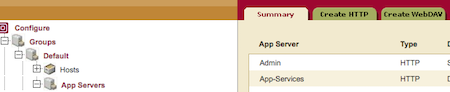
WebDav in MarkLogic konfigurieren
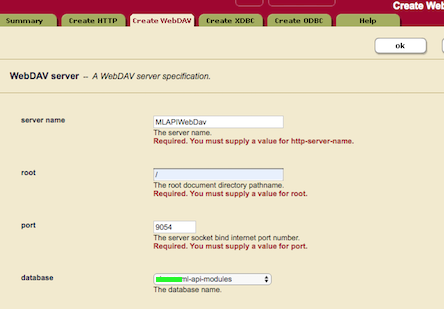
Hat man den WebDAV Server erzeugt und diesem eine bestehende oder neu angelegte Datenbank zugewiesen, dann kann man diese DB im Konfigurationsdialog der neuen WebDav Connection auswählen.
Schliesslich hat man im Data Source Explorer in oXygen die neue Verbindung verfügbar und kann gefühlt wie im Dateisystem mit den Files auf dem Server arbeiten.
Konfigurieren der WebDAV Connection Einstellungen in oXygen
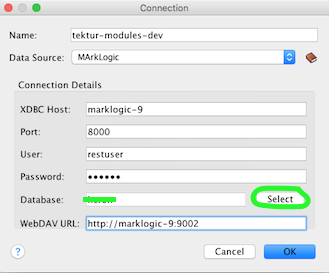
oXygen Data Source Explorer zeigt die WebDAV Verzeichnisse auf dem Marklogic Server