





- 1 Intro
- 2 Anwendungsgebiete
- 2.1 XSLT - die Programmiersprache im XML Bereich
- 2.2 Aktuelle und vergangene Anwendungen
- 2.3 Professionelle XML Verarbeitung
- 2.4 Technische Dokumentation
- 3 Wichtige Konzepte
- 3.1 Push vs. Pull Stylesheets
- 3.2 Eindeutigkeit der Regelbasis
- 3.3 Namespaces
- 3.4 Schemata
- 3.5 Standards
- 3.5.1 DITA
- 3.5.2 DITA Inhaltsmodell
- 3.5.1 DITA
- 4 Ausgewählte Themen
- 4.1 Transformationen mit XSLT
- 4.1.1 Vortransformationen
- 4.1.2 Komplexe XML-2-XML Transformationen
- 4.1.2.8 Vererbung
- 4.1.2.8 Vererbung
- 4.1.3 XSLT Streaming
- 4.1.3.1 XSLT Akkumulator
- 4.1.3.2 XSLT Iterator
- 4.1.4 Reguläre Ausdrücke
- 4.1.5 Modus vs. Tunnel Lösung
- 4.1.6 Identifikation mit
generate-id()
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.7 Webservice Calls mit doc() und unparsed-text()
- 4.1.8 Stylesheet-Parameter auf der Kommandozeile
- 4.1.9 Leerzeichenbehandlung
- 4.1.10 Mit
translate
Zeichen ersetzen
- 4.1.10.1 Spass mit dem Sequenzvergleich
- 4.1.11 Character Mappings in der Ausgabe
- 4.1.12 JSON mit XSLT 1.0 und Python lxml
- 4.1.1 Vortransformationen
- 4.2 Abfragen mit XQuery
- 4.2.5 XQuery als Programmiersprache
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.5.3.2 SQL Views in MarkLogic
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.6 Hilfreiche XQuery Schippsel
- 4.2.5 XQuery als Programmiersprache
- 4.3 XML Datenbanken
- 4.3.1 Connector zu Marklogic in Oxygen
- 4.3.2 Bi-Temporale Dokumente
- 4.3.2.1 Anlegen des Testszenarios auf der ML Konsole
- 4.3.2.2 Ausführen einiger Beispiel-Queries
- 4.3.3 Webapps mit MarkLogic
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.4 Dokument-Rechte in MarkLogic
- 4.3.5 MarkLogic Tools
- 4.3.5.1 EXPath Konsole
- 4.3.5.2 mlcp - MarkLogic Content Pump
- 4.3.5.3 Deployment-Tools
- 4.4 XSL-FO mit XSLT1.x
- 4.5 Testing
- 4.5.1 Validierung mit Schematron
- 4.5.2 Erste Schritte mit XSpec
- 4.5.1 Validierung mit Schematron
- 4.6 Performanz-Optimierung
- 4.1 Transformationen mit XSLT
- 5 Zusätzliches Know-How
- 5.1 XML Editoren
- 5.2 Quellcode-Versionskontrolle
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.2.2 GIT Kommandos
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.1 XML Editoren
- 6 Glossary
- 7 Tektur CCMS
4.3.4 Dokument-Rechte in MarkLogic
MarkLogic bietet ein sehr ausgefeiltes Rechte-und Rollensystem. Da wir MarkLogic aber vornehmlich als Datenbank einsetzen und nicht als Content Management System, reicht es aus, die grundlegende Funktionalität zu kennen.

Ohne weitere Massnahmen werden Dokumente mit den Rechten des Erzeugers versehen.

Lädt man z.B. Dokumente über die MarkLogic Content Pump in die Datenbank, wie mit diesem Befehl:
mlcp_opts="-database alex-test -host localhost -username admin -password admin"
mlcp import $mlcp_opts \
-output_permissions xml-scrapper,read,xml-scrapper,update
-input_file_path input-files \
-input_file_type aggregates \
-aggregate_record_element chapter \
-output_collections /chapter \
-output_uri_prefix /chapter/ \
-output_uri_suffix .xmlSo ist es besonders wichtig, die Einstellung:
-output_permissions role1,read,role2,update
zu setzen, wenn man z.B. für eine Webapp nur einen User mit einer bestimmten Rolle vorsieht.

Vergisst man die Option
-output_permissions
, so kann man u.U. die Dokumente von einer Webapp aus nicht zur Anzeige bringen.
In diesem Fall sind keine Rechte an den hochgeladenen Dokumenten vorhanden. Man kann diese dann in einer Webapp nur herunterladen, wenn man in der Admin-Rolle eingeloggt ist.
Es gibt einen einfachen Weg, die Rechte an einem Dokument zu überprüfen. Dazu führt man in der Konsole die "Browse"-Aktion auf einer Datenbank aus und wechselt in den Dateireiter Permissions:
Der "Browse"-Button in der MarkLogic Konsole wird oft übersehen, bietet aber viele nützliche Funktionen, wie z.b. die Anzeige der gesetzten Dokumentrechte.
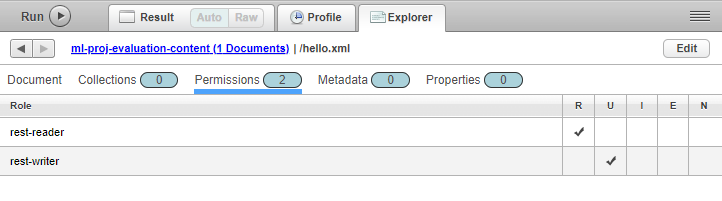
figure: 17 Anzeige der Dokument-Rechte in der MarkLogic Datenbank
Ein XQuery-Skript, das eine Webapp betreibt, kann nicht nur im Browser aufgerufen werden, sondern auch von einem externen Programm bedient werden. Damit dies möglich ist, müssen die Rechte der WebApp wie in Kapitel Wikipedia Scrapper Applikation gesetzt werden.
Idealerweise sollte man dann aber auch dem User xml-scrapper eine Rolle xml-scrapper zuweisen, die nur Dokumente mit den Permissions -output_permissions xml-scrapper,read,xml-scrapper,update, vgl. oben, lesen und modifizieren kann - und nicht die Admin-Rolle.