





- 1 Intro
- 2 Anwendungsgebiete
- 2.1 XSLT - die Programmiersprache im XML Bereich
- 2.2 Aktuelle und vergangene Anwendungen
- 2.3 Professionelle XML Verarbeitung
- 2.4 Technische Dokumentation
- 3 Wichtige Konzepte
- 3.1 Push vs. Pull Stylesheets
- 3.2 Eindeutigkeit der Regelbasis
- 3.3 Namespaces
- 3.4 Schemata
- 3.5 Standards
- 3.5.1 DITA
- 3.5.2 DITA Inhaltsmodell
- 3.5.1 DITA
- 4 Ausgewählte Themen
- 4.1 Transformationen mit XSLT
- 4.1.1 Vortransformationen
- 4.1.2 Komplexe XML-2-XML Transformationen
- 4.1.2.8 Vererbung
- 4.1.2.8 Vererbung
- 4.1.3 XSLT Streaming
- 4.1.3.1 XSLT Akkumulator
- 4.1.3.2 XSLT Iterator
- 4.1.4 Reguläre Ausdrücke
- 4.1.5 Modus vs. Tunnel Lösung
- 4.1.6 Identifikation mit
generate-id()
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.7 Webservice Calls mit doc() und unparsed-text()
- 4.1.8 Stylesheet-Parameter auf der Kommandozeile
- 4.1.9 Leerzeichenbehandlung
- 4.1.10 Mit
translate
Zeichen ersetzen
- 4.1.10.1 Spass mit dem Sequenzvergleich
- 4.1.11 Character Mappings in der Ausgabe
- 4.1.12 JSON mit XSLT 1.0 und Python lxml
- 4.1.1 Vortransformationen
- 4.2 Abfragen mit XQuery
- 4.2.5 XQuery als Programmiersprache
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.5.3.2 SQL Views in MarkLogic
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.6 Hilfreiche XQuery Schippsel
- 4.2.5 XQuery als Programmiersprache
- 4.3 XML Datenbanken
- 4.3.1 Connector zu Marklogic in Oxygen
- 4.3.2 Bi-Temporale Dokumente
- 4.3.2.1 Anlegen des Testszenarios auf der ML Konsole
- 4.3.2.2 Ausführen einiger Beispiel-Queries
- 4.3.3 Webapps mit MarkLogic
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.4 Dokument-Rechte in MarkLogic
- 4.3.5 MarkLogic Tools
- 4.3.5.1 EXPath Konsole
- 4.3.5.2 mlcp - MarkLogic Content Pump
- 4.3.5.3 Deployment-Tools
- 4.4 XSL-FO mit XSLT1.x
- 4.5 Testing
- 4.5.1 Validierung mit Schematron
- 4.5.2 Erste Schritte mit XSpec
- 4.5.1 Validierung mit Schematron
- 4.6 Performanz-Optimierung
- 4.1 Transformationen mit XSLT
- 5 Zusätzliches Know-How
- 5.1 XML Editoren
- 5.2 Quellcode-Versionskontrolle
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.2.2 GIT Kommandos
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.1 XML Editoren
- 6 Glossary
- 7 Tektur CCMS
4.3.3 Webapps mit MarkLogic
4.3.3.1 Konfiguration mit cURL
cURL ist ein gebräuchliches
Kommandozeilentool, mit dem man Web-Requests an einen Server schicken kann.

Die Beispiel-Queries auf diesen Seiten wurden größtenteils von den MarkLogic Doku-Seiten übernommen, sind jedoch
für Windows Rechner angepasst. Statt Shell Skripten mit diversen Besonderheiten, kann man die Code-Schnippsel
auch in Batch-Dateien packen und ausführen.

MarkLogic horcht auf Port
8002
mit seiner Configuration Manager Applikation. Über diesen Port können auch cURL Requests
zur Remote-Konfiguration abgesetzt werden.
Zum Anlegen einer Datenbank setzt man den folgenden cURL Befehl ab:
curl -X POST --anyauth -u admin:admin --header "Content-Type:application/json"
-d '{\"database-name\":\"xml-scrapper-content\"}'
http://localhost:8002/manage/v2/databases
Auf meiner Windows Maschine konnte ich den Befehl, wie in der MarkLogic Doku
beschrieben, nicht ausführen, da erst das JSON mittels Backslashes maskiert werden musste. Ausserdem ist in der Powershell der
curl
Befehl per alias
auf ein Windows Programm gemappt
Abhilfe: Maskieren des JSON Strings und Entfernen des cURL Aliases auf Windows.
Analog legt man einen "Forrest" an, den die oben definierte Datenbank braucht:
curl --anyauth --user alex:anoma66 -X POST -d '{\"forest-name\": \"xml-scrapper-forrest\",
\"database\": \"xml-scrapper-content\"}'
-i -H "Content-type: application/json" http://localhost:8002/manage/v2/forestsDie Konsole quittiert das erfolgreiche Ereignis mit diesen Meldungen:
HTTP/1.1 201 Created Location: /manage/v2/forests/12099403305847426321 Content-type: application/xml; charset=UTF-8 Cache-Control: no-cache Expires: -1 Server: MarkLogic Content-Length: 0 Connection: Keep-Alive Keep-Alive: timeout=5
Die Erfolgsmeldung kann man auch leicht in der Übersicht des Configuration Managers auf Port 8003 nachprüfen.
Nun können wir die neue Datenbank mit der MarkLogic Content Pump
befüllen.
Dazu laden wir folgendes Beispiel-XML, das sich in einem Ordner
input-files
befindet, in die Datenbank:
<test> <title>Test Datei</title> <chapter> <title>Test Kapitel 1</title> <content>Kapitel Inhalt 1</content> </chapter> <chapter> <title>Test Kapitel 2</title> <content>Kapitel Inhalt 2</content> </chapter> <chapter> <title>Test Kapitel 2</title> <content>Kapitel Inhalt 2</content> </chapter> </test>
Den Tippfehler im obigen XML werden wir im folgenden Kapitel korrigieren.
Das geschieht mit dem Befehl:
mlcp import -database xml-scrapper -host localhost -username admin -password admin
-input_file_path input-files -input_file_type aggregates
-aggregate_record_element chapter
-output_collections /chapter
-output_uri_prefix /chapter/
-output_uri_suffix .xmlNun brauchen wir nun noch einen Application Server in MarkLogic anlegen, um eigene XQuery Skripte laufen lassen zu können.
In einer Datei
server-setup.json
definieren wir unsere Server Einstellungen:
{ "server-name":"xml-scrapper",
"root":"c:\\xquery",
"port":"8088",
"content-database":"xml-scrapper-content",
"server-type":"http",
"group-name":"Default"
}Diese schicken wir mit dem folgenden cURL Befehl an den Server:
curl -X POST --digest -u alex:anoma66 -H "Content-type: application/json"
-d @server-setup.json http://localhost:8002/manage/v2/serversIm Web-Interface können wir uns überzeugen, dass alles geklappt hat:
Im Reiter
Configure
können wir den App Server auf MarkLogic konfigurieren.
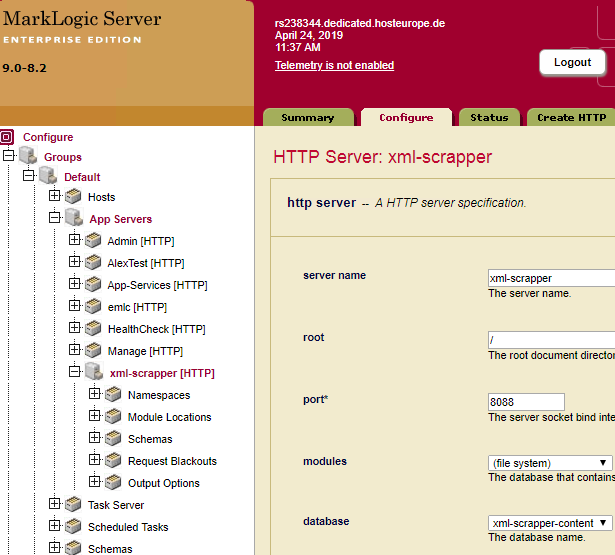
figure: 12 Konfiguration eine App Servers auf MarkLogic
Die Konfiguration kann natürlich auch mittels des Webinterfaces auf Port 8001 gemacht werden, oder aber auch per
XQuery Skripte über die Konsole auf Port 8000. Einige Skripte für diesen Zweck befinden sich auf den
Developer Seiten von MarkLogic
Nach diesen Vorbereitungen können wir unseren App-Server nun mit Skripten bestücken, wie
im folgenden Abschnitt beschrieben. Wir legen die Skripte in das Wurzelverzeichnis
c:\xquery
,
das wir oben definiert haben und können diese über einen Webrequest aufrufen, z.B. so:
http://localhost:8088/test.xqy
4.3.3.2 Implementierung als XQuery Skript
In diesem Abschnitt werden wir eine HTML Seite mit Inhaltsverzeichnis aus den zuvor geladenen Daten generieren.
Beginnen wir mit einem Skript
book.xqy
im Verzeichnis
C:\xml-scrapper
xquery version "1.0-ml"; xdmp:set-response-content-type("text/html"), let $pages := <html> <body> { for $chapter in collection("/chapter")/descendant::chapter return ( <h3>{ $chapter/title/text() }</h3>, <p>{ $chapter/content/text() }</p> ) } </body> </html> return $pages
Ergebnis: Die Kapitel der Webseite werden hintereinander weggeschrieben. Das ist natürlich noch nicht optimal
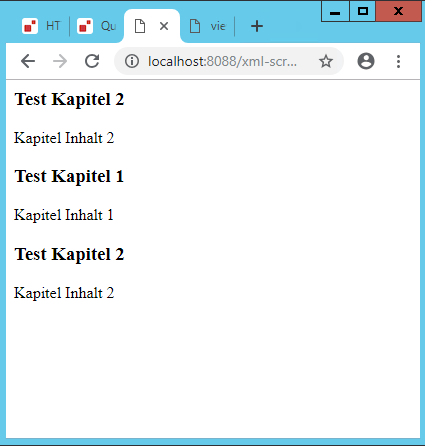
figure: 13 Erste Ausgabe unseres kleinen XQuery Skripts für eine Website
Hier fällt auf, dass wir 2x ein Kapitel 2 eingebunden haben. Es handelt sich dabei um einen Tippfehler.
Wir kümmern uns um diesen Fehler später.
Nun wollen wir die einzelnen Seiten auf verschiedene Webseiten aufsplitten und auf einer Cover-Page ein Inhaltsverzeichnis
darstellen.
xquery version "1.0-ml"; declare variable $page:= xdmp:get-request-field('page'); xdmp:set-response-content-type("text/html"), let $page-id := if ($page) then $page else ('cover'), $pages := <html> <body> { <h3>Welcome to The Book</h3>, for $chapter at $position in collection("/chapter")/descendant::chapter return ( if ($page-id = 'cover') then ( <p><a href="?page={$position}">{ $chapter/title/text() }</a></p> ) else ( (: TODO :) ) ) } </body> </html> return $pages
Im Vergleich zu einer XSLT Lösung stellt man fest, dass man vergeblich versucht die XPath Funktion
fn:position()
anzuwenden. Stattdessen verwendet man das Schlüsselwort
at
in der
for
Loop.
Auf der initialen Cover-Seite wird nun ein verlinktes Inhaltsverzeichnis angezeigt:
Der zweite Schritt unserer Webapplikation ist ein Inhaltsverzeichnis mit verlinkten Kapiteln
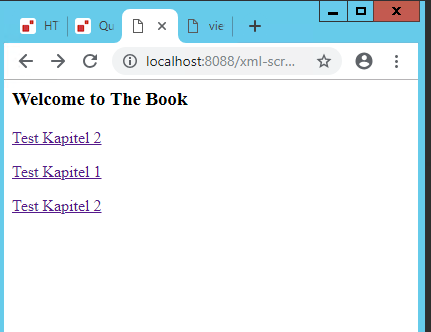
figure: 14 Zweite Ausgabe unseres kleinen XQuery Skripts für eine Website
Der im Skript deklarierte Request-Parameter
$page
wird nun ausgewertet, um die Kapitelseiten zu erzeugen.
xquery version "1.0-ml"; declare variable $page:= xdmp:get-request-field('page'); xdmp:set-response-content-type("text/html"), let $page-id := xs:decimal(if ($page) then $page else '0'), $pages := collection("/chapter"), $website := <html> <body> { <h3>Welcome to The Book</h3>, for $chapter at $position in $pages/descendant::chapter return ( if ($page-id lt 1 or $page-id gt count($pages)) then ( <p><a href="?page={$position}">{ $chapter/title/text() }</a></p> ) else if ($page-id = $position) then ( <h2>{ $chapter/title/text() }</h2>, <p>{ $chapter/content/text() }</p>, <p><a href="{ xdmp:get-request-path() }">Back To Cover</a></p> ) else () ) } </body> </html> return $website
Hier ist das
at
Schlüsselwort interessant mit dem man die Position in der Schleife abgreifen kann.
fn:position()
wie bei XSLT gebräuchlich würde hier nicht funtktionieren. Dass wir bedingte
Anweisungen in funktionalen Sprachen als Ausdruck auswerten können, haben wir in hier schon gelernt,
vgl. die
sx:decimal
Cast Anweisung zur Typ-Konvertierung.
Unsere Website wäre eigentlich schon perfekt, wenn da der fehlerhafte Datenimport nicht wäre, und wir das Kapitel 2 nicht
doppelt importiert hätten. Um die Daten zu bereinigen ist eine Daten-Migration notwendig.
4.3.3.3 Webapps mit mehreren Datenbanken
Jeder App-Server ist in MarkLogic genau einer Content-Database zugeordnet.
Darin sollten alle Daten vorhanden sein, auf die die Webapplikation zugreift.
Es ist jedoch über einen kleinen "Hack" möglich andere Datenbanken in derselben
MarkLogic Webapp abzufragen. Dazu verwendet man die
xdmp:eval-in
Funktion.
Wie der Name schon sagt, wird damit ein Ausdruck in einer anderen Datenbank evaluiert.
Das Beispiel dazu auf der MarkLogic-Doku Seite
sieht folgendermassen aus:
xquery version "0.9-ml" declare namespace my='http://mycompany.com/test' let $s := "xquery version '0.9-ml' declare namespace my='http://mycompany.com/test' define variable $my:x as xs:string external concat('hello ', $my:x)" return (: evaluate the query string $s using the variables supplied as the second parameter to xdmp:eval :) xdmp:eval-in($s, xdmp:database("Documents"), ("my:x"), "world")) => hello world
Ein Anwendungsbeispiel aus der Praxis würde demnach so aussehen:
declare function local:remove-sql-view($sql-view-name) { let $url := concat('/sql-views/', $sql-view-name) return xdmp:eval-in('xquery version "1.0-ml"; declare variable $url as xs:string external; xdmp:document-delete($url), xdmp:schema-database(), ('url'),$url) ) };
Hier wird eine zuvor gesetzte SQL View, vgl. Kapitel SQL Views in MarkLogic , die per Default
in der Schema-Datenbank untergebracht ist, wieder aus dem System gelöscht.
4.3.3.4 Datenkorrektur mit der Konsole
Um die fehlerhaften Daten aus dem vorherigen Kapitel zu korrigieren, öffnen wir eine Konsolensitzung auf Port
8000
:
Wir bemerken in der folgenden Abbildung, dass das
mlcp
Kommando den
document-name
mit dem absoluten Pfad der Datei im
Dateisystem des importierenden Rechners geprefixt hat.
Auf der Konsole können wir uns die in der Collection abgespeicherten Dokumente auflisten lassen.
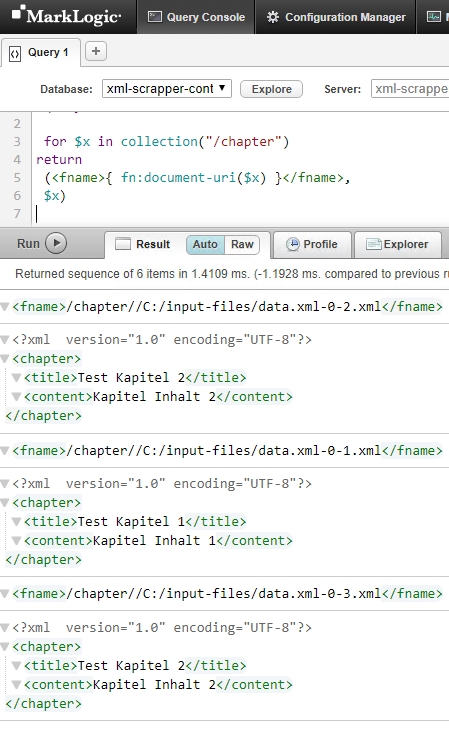
figure: 15 MarkLogic Konsolensitzung mit einer Collection Iteration
Wir sehen, dass wir zweimal ein Kapitel 2 in der Collection angelegt haben. Wir müssen also das 3. Element in der
Collection korrigieren:
xdmp:node-replace(doc("/chapter//C:/input-files/data.xml-0-3.xml")/chapter/title, <title>Test Kapitel 3</title>); xdmp:node-replace(doc("/chapter//C:/input-files/data.xml-0-3.xml")/chapter/content, <title>Kapitel Inhalt 3</title>);
Das Semikolon zum Abschluss des Statements ist eine Besonderheit von MarkLogic und gibt an, dass
dieses Statement in einer Transaktion ausgeführt werden soll.
In anderen XQuery Implementierungen gibt es diese Funktion möglicherweise nicht.
Nach dieser Korrektur sollten die Daten wieder stimmen und unsere Webapp ist fertig...