





- 1 Intro
- 2 Anwendungsgebiete
- 2.1 XSLT - die Programmiersprache im XML Bereich
- 2.2 Aktuelle und vergangene Anwendungen
- 2.3 Professionelle XML Verarbeitung
- 2.4 Technische Dokumentation
- 3 Wichtige Konzepte
- 3.1 Push vs. Pull Stylesheets
- 3.2 Eindeutigkeit der Regelbasis
- 3.3 Namespaces
- 3.4 Schemata
- 3.5 Standards
- 3.5.1 DITA
- 3.5.2 DITA Inhaltsmodell
- 3.5.1 DITA
- 4 Ausgewählte Themen
- 4.1 Transformationen mit XSLT
- 4.1.1 Vortransformationen
- 4.1.2 Komplexe XML-2-XML Transformationen
- 4.1.2.8 Vererbung
- 4.1.2.8 Vererbung
- 4.1.3 XSLT Streaming
- 4.1.3.1 XSLT Akkumulator
- 4.1.3.2 XSLT Iterator
- 4.1.4 Reguläre Ausdrücke
- 4.1.5 Modus vs. Tunnel Lösung
- 4.1.6 Identifikation mit
generate-id()
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.7 Webservice Calls mit doc() und unparsed-text()
- 4.1.8 Stylesheet-Parameter auf der Kommandozeile
- 4.1.9 Leerzeichenbehandlung
- 4.1.10 Mit
translate
Zeichen ersetzen
- 4.1.10.1 Spass mit dem Sequenzvergleich
- 4.1.11 Character Mappings in der Ausgabe
- 4.1.12 JSON mit XSLT 1.0 und Python lxml
- 4.1.1 Vortransformationen
- 4.2 Abfragen mit XQuery
- 4.2.5 XQuery als Programmiersprache
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.5.3.2 SQL Views in MarkLogic
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.6 Hilfreiche XQuery Schippsel
- 4.2.5 XQuery als Programmiersprache
- 4.3 XML Datenbanken
- 4.3.1 Connector zu Marklogic in Oxygen
- 4.3.2 Bi-Temporale Dokumente
- 4.3.2.1 Anlegen des Testszenarios auf der ML Konsole
- 4.3.2.2 Ausführen einiger Beispiel-Queries
- 4.3.3 Webapps mit MarkLogic
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.4 Dokument-Rechte in MarkLogic
- 4.3.5 MarkLogic Tools
- 4.3.5.1 EXPath Konsole
- 4.3.5.2 mlcp - MarkLogic Content Pump
- 4.3.5.3 Deployment-Tools
- 4.4 XSL-FO mit XSLT1.x
- 4.5 Testing
- 4.5.1 Validierung mit Schematron
- 4.5.2 Erste Schritte mit XSpec
- 4.5.1 Validierung mit Schematron
- 4.6 Performanz-Optimierung
- 4.1 Transformationen mit XSLT
- 5 Zusätzliches Know-How
- 5.1 XML Editoren
- 5.2 Quellcode-Versionskontrolle
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.2.2 GIT Kommandos
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.1 XML Editoren
- 6 Glossary
- 7 Tektur CCMS
4.3.5.2 mlcp - MarkLogic Content Pump
Die Content Pump für MarkLogic ist ein Java Tool, das den Bulk-Import von Daten über die Kommadozeile realisiert.
Das betreffende GitHub Projekt befindet sich hier ↗.
Zur einfachen Installation kann man sich aber auch die Binaries auf den
Developer Seiten ↗ herunterladen.
Folgendes Bash Skript benutze ich, um Daten nach MarkLogic hochzuladen:
#!/bin/bash
set -eo pipefail
mlcp_opts="-database alex-test -host localhost -username admin -password admin"
mlcp import $mlcp_opts \
-input_file_path input-files \
-input_file_type aggregates \
-aggregate_record_element chapter \
-output_collections /chapter \
-output_uri_prefix /chapter/ \
-output_uri_suffix .xmlDabei werden alle Dateien im Ordner
input-files
importiert. Der Dateityp
der hochzuladenen Daten ist mit
aggregates
angegeben. Das sind XML Daten.

Mehr Infos zu den Kommandozeilen-Optionen befinden sich auf der
entsprechenden Dokuseite ↗
von MarkLogic.

Mit der Option
-aggregate_record_element
wird definiert, dass die Eingabe bzgl. des Elements
<chapter>
aufgesplittet werden soll.
D.h. eine Datei mit folgendem Inhalt:
<test> <title>Test Datei</title> <chapter> <title>Test Kapitel 1</title> <content>Kapitel Inhalt 1</content> </chapter> <chapter> <title>Test Kapitel 2</title> <content>Kapitel Inhalt 2</content> </chapter> <chapter> <title>Test Kapitel 2</title> <content>Kapitel Inhalt 2</content> </chapter> </test>
wird in drei Records aufgesplittet:
Auf der Konsole kann man sich das Ergebnis der
mlcp
Sitzung anschauen. Es wurden - wie gewünscht - drei XML Fragmente separat in die Collection gespeichert.
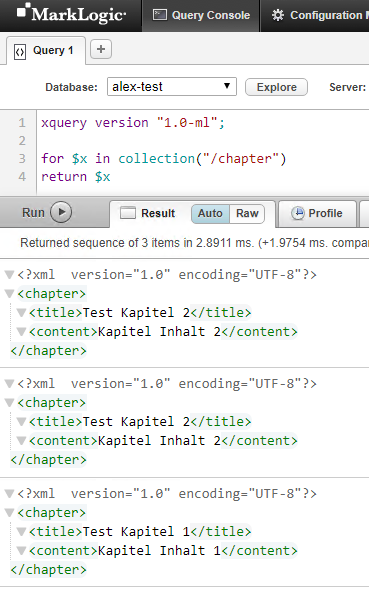
figure: 20 Ergebnis einer MarkLogic Content Pump Sitzung
Um in MarkLogic keine Speicherpobleme zu erzeugen empfielt es sich große Dokumente, die man nur "speichern" will mit der Option
-document_type binary
zu importieren. In diesem Zusammenhang ist ebenfalls die Option
-streaming true
interessant.
Ein weiterer wichtiger Punkt, der mir bei der Arbeit mit
mlcp
aufgefallen ist:

Kommt es zu Inkonsistenzen in der Datenhaltung, mag das daran liegen, dass in verschiedenen
mlcp
Sitzungen von der gleichen Datei (gleicher Dateiname im Filesystem) importiert wurde.
Es ist darauf zu achten, dass die Dateinamen eindeutig sind. Das kann zum Beispiel durch die Vergabe einer eindeutige ID im Dateinamen geschehen. Auf der Dokuseite zu den
mlcp
Optionen steht dazu folgendes:
"If your aggregate URI id's are not unique, you can overwrite one document in your input set with another. Importing documents with non-unique URI id's from multiple threads can also cause deadlocks."
"The generated URIs are unique across a single import operation, but they are not globally unique. For example, if you repeatedly import data from some file /tmp/data.csv, the generated URIs will be the same each time (modulo differences in the number of documents inserted by the job)"