





- 1 Intro
- 2 Anwendungsgebiete
- 2.1 XSLT - die Programmiersprache im XML Bereich
- 2.2 Aktuelle und vergangene Anwendungen
- 2.3 Professionelle XML Verarbeitung
- 2.4 Technische Dokumentation
- 3 Wichtige Konzepte
- 3.1 Push vs. Pull Stylesheets
- 3.2 Eindeutigkeit der Regelbasis
- 3.3 Namespaces
- 3.4 Schemata
- 3.5 Standards
- 3.5.1 DITA
- 3.5.2 DITA Inhaltsmodell
- 3.5.1 DITA
- 4 Ausgewählte Themen
- 4.1 Transformationen mit XSLT
- 4.1.1 Vortransformationen
- 4.1.2 Komplexe XML-2-XML Transformationen
- 4.1.2.8 Vererbung
- 4.1.2.8 Vererbung
- 4.1.3 XSLT Streaming
- 4.1.3.1 XSLT Akkumulator
- 4.1.3.2 XSLT Iterator
- 4.1.4 Reguläre Ausdrücke
- 4.1.5 Modus vs. Tunnel Lösung
- 4.1.6 Identifikation mit
generate-id()
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4.1 Funktionen und Module
- 4.1.6.4 XPath-Achsenbereich selektieren
- 4.1.7 Webservice Calls mit doc() und unparsed-text()
- 4.1.8 Stylesheet-Parameter auf der Kommandozeile
- 4.1.9 Leerzeichenbehandlung
- 4.1.10 Mit
translate
Zeichen ersetzen
- 4.1.10.1 Spass mit dem Sequenzvergleich
- 4.1.11 Character Mappings in der Ausgabe
- 4.1.12 JSON mit XSLT 1.0 und Python lxml
- 4.1.1 Vortransformationen
- 4.2 Abfragen mit XQuery
- 4.2.5 XQuery als Programmiersprache
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.5.3.2 SQL Views in MarkLogic
- 4.2.5.3
if..then..else
Ausdrücke
- 4.2.6 Hilfreiche XQuery Schippsel
- 4.2.5 XQuery als Programmiersprache
- 4.3 XML Datenbanken
- 4.3.1 Connector zu Marklogic in Oxygen
- 4.3.2 Bi-Temporale Dokumente
- 4.3.2.1 Anlegen des Testszenarios auf der ML Konsole
- 4.3.2.2 Ausführen einiger Beispiel-Queries
- 4.3.3 Webapps mit MarkLogic
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.3.5 Wikipedia Scrapper Applikation
- 4.3.4 Dokument-Rechte in MarkLogic
- 4.3.5 MarkLogic Tools
- 4.3.5.1 EXPath Konsole
- 4.3.5.2 mlcp - MarkLogic Content Pump
- 4.3.5.3 Deployment-Tools
- 4.4 XSL-FO mit XSLT1.x
- 4.5 Testing
- 4.5.1 Validierung mit Schematron
- 4.5.2 Erste Schritte mit XSpec
- 4.5.1 Validierung mit Schematron
- 4.6 Performanz-Optimierung
- 4.1 Transformationen mit XSLT
- 5 Zusätzliches Know-How
- 5.1 XML Editoren
- 5.2 Quellcode-Versionskontrolle
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.2.2 GIT Kommandos
- 5.2.1 Kurze Geschichte zur Versionskontrolle Test
- 5.1 XML Editoren
- 6 Glossary
- 7 Tektur CCMS
4.3.3.5 Wikipedia Scrapper Applikation
In diesem Kapitel wollen wir eine XSLT Transformation bauen, die während des Durchlaufs durch einen XML Baum Anfragen
an ein XQuery Skript auf einem MarkLogic Server stellt. Über einen GET Request wird ein Feld
<title>
zur Persistierung
in einer ML Collection übertragen.
4.3.3.5.1 App Server Authentifizierung
Um dieses Szenario realisieren zu können, müssen wir die Rechte in MarkLogic so einstellen, dass Webrequests ohne eine
Authentifizierung akzeptiert werden. D.h. unsere Applikation ist also eher für den internen Gebrauch gedacht.
Da momentan der Saxon XSLT Prozessor die Auflösung von URIs dem Java URI Resolver überlässt, dieser aber eine Authentifizierung mit Credentials in der URL, wie in
fn:json-to-xml('http://admin:admin@localhost:8088')noch nicht unterstützt, müssen wir die Authentifizierung für unsere MarkLogic Webapp ausschalten.
Dazu setzen wir
die Einstellung
authentication
unseres App Servers auf
application-level
und weisen
die Default-User Rolle einem
admin
Benutzer zu.
In der App Server Konfiguration kann man die Stufe einstellen, auf der der Zugriffsmechanismus greifen soll. Hier stellen wir
application-level
mit einem Admin-User ein, um für das Intranet die Authentifizierung auszuschalten.
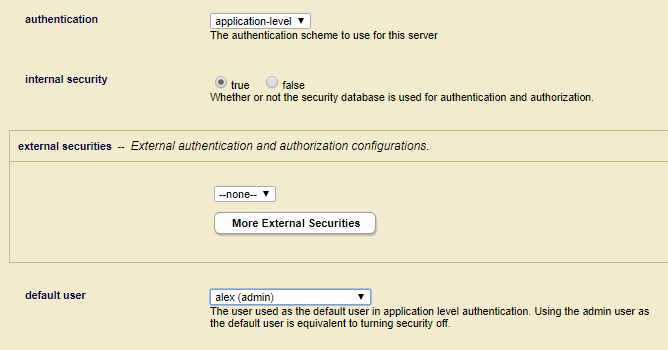
figure: 16 MarkLogic App Server Authentifizierung einstellen
Eine ausgefeiltere Einstellung wird im Kapitel Dokument-Rechte in MarkLogic beschrieben.
4.3.3.5.2 XML Eingabe
Damit das Experiment etwas aufregender wird, arbeiten wir mittels XML Streaming auf einem Wikipedia Dump mit 5.3 GB
Filesize ↗.
Das XML dazu sieht folgendermassen aus:
<mediawiki xmlns="http://www.mediawiki.org/xml/export-0.10/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.10/ http://www.mediawiki.org/xml/export-0.10.xsd" version="0.10" xml:lang="en"> <siteinfo> <sitename>Wikipedia</sitename> <dbname>enwiki</dbname> <base>https://en.wikipedia.org/wiki/Main_Page</base> <generator>MediaWiki 1.29.0-wmf.12</generator> <case>first-letter</case> <namespaces> [...] </namespaces> </siteinfo> <page> <title>AccessibleComputing</title> <ns>0</ns> <id>10</id> <redirect title="Computer accessibility" /> <revision> <id>631144794</id> <parentid>381202555</parentid> <timestamp>2014-10-26T04:50:23Z</timestamp> <contributor> <username>Paine Ellsworth</username> <id>9092818</id> </contributor> [...]
Wir wollen alle Titel in einer Datenbank speichern, deshalb wird auf das
<title>
Element gematcht.
4.3.3.5.3 XSLT Transformation
Die Streaming Transformation mit dem Iterator Konzept sieht so aus:
template name="main"> <xsl:source-document href="{$input-file}" streamable='yes'> <result> <xsl:iterate select="page/title"> <xsl:variable name="json-call" select="json-to-xml( unparsed-text( concat($server-url,'/scrap-title.xqy?', 'title=',encode-for-uri(.))))"/> <state> <xsl:sequence select="$json-call/descendant::*[@key='state']/text()"/> </state> </xsl:iterate> </result> </xsl:source-document> </xsl:template>
Hier werden in einer Ergebnis Struktur mit einem
<result>
Element einzelne
<state>
Elemente ausgegeben.
Der Inhalt dieser Elemente ist Rückgabewert eines Webrequests über die Funktion
fn:unparsed-text()
.
An das Skript
scrap-title.xqy
wird ein Parameter
title
übergeben:
xquery version "1.0-ml"; import module namespace json = "http://marklogic.com/xdmp/json" at "/MarkLogic/json/json.xqy"; declare namespace local = 'local:'; declare variable $title := xdmp:get-request-field('title'); declare function local:render-response($response) { xdmp:add-response-header("Pragma", "no-cache"), xdmp:add-response-header("Cache-Control", "no-cache"), xdmp:add-response-header("Expires", "0"), xdmp:set-response-content-type('text/json; charset=utf-8'), xdmp:unquote($response) }; let $root := <title>{ $title }</title>, $options := <options xmlns="xdmp:document-insert"> <permissions>{ xdmp:default-permissions() }</permissions> <collections> <collection>/wikimedia-titles</collection> </collections> </options>, $fname := concat('/wikimedia-titles/', xdmp:md5($title), ".xml"), $td := xdmp:document-insert($fname, $root, $options) return local:render-response(concat('{"state":"success","title":"',$title,'"}'))
Wenn alles gut läuft, sollte die Transformation nach einer halben Stunde abgeschlossen sein. Es sollten sich in der
Collection
/wikimedia-titles
viele Einträge befinden, mit Dateinamen wie:
<fname>/wikimedia-titles/b00bb36cf9dd18f12141f463f59947e6.xml</fname>